How to analyse reaction time (RT) data: Part 1
 Reaction time tasks have been a mainstay of psychology since the technology to accurately time and record such responses became widely available in the 70s. RT tasks have been applied in a bewildering array of research areas and (when used properly) can provide information about memory, attention, emotion and even social behaviour.
Reaction time tasks have been a mainstay of psychology since the technology to accurately time and record such responses became widely available in the 70s. RT tasks have been applied in a bewildering array of research areas and (when used properly) can provide information about memory, attention, emotion and even social behaviour.
This post will focus on the best way to handle such data, which is perhaps not as straightforward as might be assumed. Despite the title, I’m not really going to cover the actual analysis; there’s a lot of literature already out there about what particular statistical tests to use, and in any case, general advice of that kind is not much use as it depends largely on your experimental design. What I’m intending to focus on are the techniques the stats books don’t normally cover – data cleaning, formatting and transformation techniques which are essential to know about if you’re going to get the best out of your data-set.
For the purposes of this discussion I’ll use a simple made-up data-set, like this:
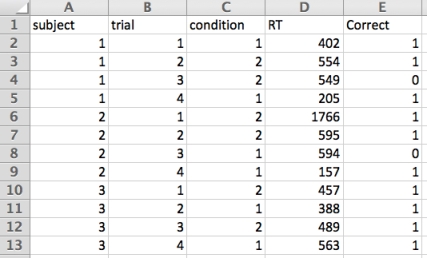
This table is formatted in the way that a lot of common psychology software (i.e. PsychoPy, Inquisit, E-Prime) records response data. From left-to-right, you can see we have three participants’ data here (1, 2, and 3 in column A), four trials for each subject (column B), two experimental conditions (C; presented in a random order), and then the actual reaction times (column D) and then a final column which codes whether the response was correct or not (1=correct, 0= error).
I created the data table using Microsoft Excel, and will do the processing with it too, however I really want to stress that Excel is definitely not the best way of doing this. It suits the present purpose because I’m doing this ‘by hand’ for the purposes of illustration. With a real data-set which might be thousands of lines long, these procedures would be much more easily accomplished by using the functions in your statistics weapon-of-choice (SPSS, R, Matlab, whatever). Needless to say, if you regularly have to deal with RT data it’s well worth putting the time into writing some general-purpose code which can be tweaked and re-used for subsequent data sets.
The procedures we’re going to follow with these data are:
- Remove reaction times on error trials
- Do some basic data-cleaning (removal of outlying data)
- Re-format the data for analysis
1. Remove reaction times on error trials
As a general rule, reaction times from trials on which the participant made an error should not be used in subsequent analysis. The exceptions to this rule are some particular tasks where the error trials might be of particular interest (Go/No-Go tasks, and some others). Generally though, RTs from error trials are thought to be unreliable, since there’s an additional component process operating on error trials (i.e. whatever it was that produced the error). The easiest way of accomplishing this is to insert an additional column, and code all trials with errors as ‘0’, and all trials without an error as the original reaction time. This can be a simple IF/ELSE statement of the form:
IF (error=1) RT=RT,
ELSE RT=0
In this excel-based illustration I entered the formula: =IF(E2=1, D2,0) in cell F2, and then copied it down the rest of the column to apply to all the subsequent rows. Here’s the new data sheet:

2. Data-cleaning – Removal of outlying data
The whole topic of removing outliers from reaction time data is a fairly involved one, and difficult to illustrate with the simple example I’m using here. However, It’s a very important procedure, and something I’m going to return to in a later post, using a ‘real’ data-set. From a theoretical perspective, it’s usually desirable to remove both short and long outliers. Most people cannot push a button in response to, say, a visual stimulus in less than about 300ms, so it can be safely assumed that short RTs of, say, less than 250ms were probably initiated before the stimulus; that is, they were anticipatory. Long outliers are somewhat trickier conceptually – some tasks that involve a lot of effortful cognitive processing before a response (say a task involving doing difficult arithmetic) might have reaction times of several seconds, or even longer. However, very broadly, the mean RT for most ‘simple’ tasks tends to be around 400-700ms; this means that RTs longer than say, 1000ms might reflect some other kind of process. For instance, it might reflect the fact that the participant was bored, became distracted, temporarily forgot which button to push, etc. For these reasons then, it’s generally thought to be desirable to remove outlying reaction times from further analysis.
One (fairly simple-minded, but definitely valid) approach to removing outliers then, is to simply remove all values that fall below 250ms, or above 1000ms. This is what I’ve done in the example data-sheet in columns G and H, using simple IF statements of a similar form used for removal of the error trials:

You can see that two short RTs and one long one have been removed and recoded as 0.
3. Re-format the data for analysis
The structure that most psychology experimental systems use for their data logging (similar to the one we’ve been using as an illustration) is not really appropriate for direct import into standard stats packages like SPSS. SPSS requires that one row on the data sheet is used for each participant, whereas we have one row-per-trial. In order to get our data in the right format we first need to sort the data, first by subject (column A), and then by condition (column C). Doing this sort procedure ensures that we know which entries in the final column are which – the first two rows of each subject’s data are always condition 1, and the second two are always condition 2:

We can then restructure the data from the final column, like so:

I’ve done this ‘by hand’ in Excel by cutting-and-pasting the values for each subject into a new sheet and using the paste-special > transpose function, however this is a stupid way of doing it – the ‘restructure’ functions in SPSS can accomplish this kind of thing very nicely. So, our condition 1 values are now in columns B:C and condition 2 values are in columns D:E. All that remains to do now would be to calculate summary statistics (means, variance, standard deviations, whatever; taking care that our 0 values are coded as missing, and not included in the calculations) for each set of columns (i.e. each condition) and perform the inferential tests of your choice (in this case, with only two within-subject conditions, it would be a paired t-test).
Next time, I’ll use a set of real reaction time data and do these procedures (and others) using SPSS, in order to illustrate some more sophisticated ways of handling outliers than just the simple high and low cutoffs detailed above.
TTFN.
Posted on December 11, 2012, in Experimental techniques, Software, Study Skills and tagged analysis, experiment, reaction time, research, response time, statistics. Bookmark the permalink. 20 Comments.

Hi Matt, isn’t it a bit dangerous to insert zeros into the data to represent invalid trials? Those values will still need to be filtered out again in the analysis stage to avoid contaminating your means, standard deviations, etc. So the step of identifying the invalid trials needs to be done twice, which doesn’t save any time in the analysis. Wouldn’t it be better to replace those with blanks cells (“” in Excel parlance), so that your filtering happens only once?
Also, the SuperPower (TM pending) for Excel in preprocessing data is the Pivot Table. That is a great way of reformatting tabular data into the various forms required for other software. It is graphical and interactive, so you can instantly see if it is in the format required. It will totally avoid your manual cutting and pasting, which needs to re-done whenever the data is altered, whereas Pivot Tables can auto-update in response to new source data being added or changed. Also Picot Tables include the ability to filter data, so could also avoid your manual filtering via formulae.
Even without using Pivot Tables (which are REALLY worth getting to grips with if Excel is in your processing pipeline), simple data filters would allow the temporary removal of invalid trials (on single or multiple criteria), without the need to create additional columns via formulae. Excel formulae can be very useful for more complex needs, but I think are a bit too much work here given what Excel gives one “for free” via point & click functionality.
Cheers,
Mike
I also love Pivot Tables, but if you’re like me and don’t quite like moving between Python and Excel just for data analysis, a package called pandas has Pivot Table functionality (including easy plotting). It also makes it trivial to remove outliers or filter data in other ways. For example, if your dataset is stored in a variable df, then df[df.RT>250] will display only the entries with RT values above 250 ms.
I’m more of an ex-Excel user these days, and just use pivot tables for management-type tasks, and simple student projects where the barrier to entry of R is not justified.
So thanks for the pointer to pandas. Although I use Python (specifically PsychoPy http://www.psychopy.org/ ) for data collection, I rely on R for data analysis. Python is a much nicer language, but it doesn’t seem that pandas can do the modeling I need (and I’m also wedded to the excellent ggplot http://ggplot2.org/ package for graphing). And I’m not sure that I’m cognitively flexible enough to try a hybrid solution, but will look into it further. Cheers.
Hi Jonas, thanks for the tip – Pandas looks very cool indeed for Pythoneers. I’ll add it to my links page.
Mike,
Many thanks for the comments – really useful feedback. I was a little unsure about how to approach this topic really. What I wanted to achieve was a fairly abstract outline of the processes involved, rather than a step-by-step kind of approach, which is necessarily tied to a particular package. In reality I would NEVER do this kind of thing on ‘real’ data in Excel, but it seemed like the easiest way of illustrating the process… Maybe this was misguided, and I should have taken a different approach.
>isn’t it a bit dangerous to insert zeros into the data to represent invalid trials? Those >values will still need to be filtered out again in the analysis stage to avoid >contaminating your means, standard deviations, etc. So the step of identifying the >invalid trials needs to be done twice, which doesn’t save any time in the analysis. >Wouldn’t it be better to replace those with blanks cells (“” in Excel parlance), so that >your filtering happens only once?
Yes, good point. What I’ve generally done in the past is zero everything during pre-processing, and then define 0 as a missing value for the relevant variables in SPSS, so that summary measures aren’t contaminated. Can’t see any particular advantage for doing that though, so I guess it’s just habit! I left the 0s in for illustrative purposes here as well – think it’s easier to see what’s going on than if there’s just empty cells.
Agreed about Pivot Tables as well – I’ve used the function a little bit in the past, and it’s extremely powerful. However, what I was trying to do here was illustrate the concepts in a step-by-step way, so it seemed clearer to do it ‘by hand’ rather than say ‘and now use pivot tables to do everything’.
Maybe this abstracted approach with made-up data is not very useful though… I’m thinking now that perhaps I should have started off with ‘proper’ data and done it ‘properly’.
Many thanks again for the feedback!
M.
If you’re interested in analysing RT data some additional reading:
Field, A. P., & Wright, D. B. (2011). A Primer on Using Multilevel Models in Clinical and Experimental Psychopathology Research. Journal of Experimental Psychopathology., 2(2), 271-293. doi: 10.5127/jep.013711
Ratcliff, R. (1993). Methods for Dealing with Reaction-Time Outliers. Psychological Bulletin, 114(3), 510-532.
andy
Thanks Andy! The Ratcliff paper is a *classic* and I was planning on going through it in my next post when I talk about outliers in more detail. Will take a look at your recent paper before I do that one as well though…
M.
A very interesting and somewhat vexed topic.
My work with Roger Carpenter in the UK has changed the way I analyse reaction times.
See http://www.cudos.ac.uk/later.htm for a description of the LATER model which applies equally well to saccadic latency as to manual responses.
Prof Carpenter’s key points are:
– be very careful aggregating inter-subject data, often individual distributions are more illustrative.
– the distributions can be linearlised by plotting cumulative probability vs inverse latency (ie: a reciprobit plot) and these distributions can allow meaningful analysis and comparison (using Kolmogorov Smirnov test).
R is a wonderful program for plotting and comparing these distributions, see this snippet in stack overflow for some basic plots:
http://stackoverflow.com/questions/11470579/transforming-axis-labels-with-a-multiplier-ggplot2
and this blog post for more on R and plotting: http://f.giorlando.org/software-for-research-part-3-r-rstudio-and-ggplot2-for-statistics
With the richness found in these methods, it seems a pity to look at less illustrative metrics like average latency.
Also, as a general principle of statistical analysis, it’s good to keep your raw data untouched and transformations should happen via explicit scripting on this data. The analysis path is reproducible in this manner and less prone to errors.
A subject for another day (and an upcoming blog post), but there are now good computation tools to handle much of the analysis path automatically (or more specifically algorithmically),
eg: data acquisition -> import and preprocess with R -> output and format with LaTeX/knitr
This allows a single script to produce formatted, publication ready, statistical output with graphics and tests for raw data of the specified format rather than manually transforming the data through a string of user interventions that can introduce obscurity and errors.
Dr. Wall:
What you post is very clear and useful. You mentioned that “one approach to removing outliers then, is to simply remove all values that fall below 250ms, or above 1000ms.” Would you please provide the reference if there’s any? Or it’s an judgment out of your research experience? Thank you very much!
Eric
Hi Eric,
Those values of 250ms and 1000ms are pretty-much just ‘common-sense’ values for a ‘typical’ RT experiment. It’s pretty difficult to envisage a situation where people could routinely respond faster than 250ms, but for a lot of experiments (i.e. stroop tasks, or clinical studies with older patients, etc.) their normal (i.e. non-outlier) RTs could well be routinely more than 1000ms. The best guide is drawing some box-and-whisker plots of your RT data, looking at where the ends of the upper ‘whiskers’ fall, and choosing a cut-off value that maximises the amount of ‘good’ data that’s retained and the amount of ‘bad’ (i.e. outlier) data that’s excluded.
M.
Dr. Wall,
Many thanks for your sharing. You have given me very good ideas.
Eric
I keep coming across this and wishing for more, I’m currently trying to work with the accuracy portion of my reaction time data and finding it a total nightmare to get it ready for analysis in SPSS.
I’m a second year MA student of Applied Linguistics. I have been reading your posts about psychopy and RT data, very helpful. I’am working on my MA disseration in which I intend to answer similar research questions to Fitzpatrick and Izura (2011).
I used an (L2) word association task followed by a lexical decision task in which prime words( L1 translation equivalents of some words previously given as stimulus words in the L2 word association test), non-prime words, and nonwords are presented to participants. I intend to assess the priming effect and whether it is affected by the proficiency level of participants. The researchers stated that they used ANOVA with proficiency as a between-subjects factor and priming as a within-subjects factor. Could you please help me understand how they operationalized the “priming” factor !!! Thank you very much in advance, I would really appreciate if you will answer me as soon as possible. I am a beginner with statistics and all, so please if anyone is willing to see the article and be patient in answering some other questions i will be very greatful.
Hi,
Sorry for the delay in getting back to you. Email me the paper you’re talking about and the questions you have and I’ll do my best to answer them: mbwall [at] gmail [dot] com.
M.
Thank you very much dear Wall, would you please check your email !!
Patience… I’m getting to it… ;o)
Do you have a suggested reference from the cleaning procedure?
Hi Matt,
Thanks for the informative posts. I’m currently working on analysing some dual task reaction time data that I’ve collected, and (as you said!) it’s not as straightforward as I’d hoped. I’m using E-Prime to collect my Data, and my participants technically have a 2000 ms window in which they CAN respond. I’ve decided to set my max at 1000 ms. When I’m cleaning up the data – is it better to simply eliminate all response above 1000 ms, or can I assign all of those high values as 1000 ms? I originally just eliminated them, but this seems to artificially decrease the participant’s reaction times, and doesn’t reflect the group differences that I am observing as I collect data, once I run the ‘cleaned’ stats.
Then, of course, if I do this – I’m not sure how to treat instances where the participant simply didn’t respond. Am currently just treating this as a ‘0’, but if I assign the outliers as above a 1000 ms value, should I do this for the missed intervals as well?
I REALLY appreciate any input!
Hi Rebecca,
Sorry for the delay in responding. The standard thing to do is to remove outliers from the data-set, so in your case anything above 1000ms wouldn’t be ‘counted’ in terms of calculating the mean reaction times for your groups/conditions. People do sometimes replace outlying data with other values – either with the cut-off value (as you mentioned) or with the mean for that subject – somewhat unusual though. The normal procedure is to replace any problematic trials (either long outliers, or no-responses) with a standard value (e.g. 0) and then set that value as a ‘missing value’ in your stats software, so that it’s not counted.
You should choose your cut-off value carefully though. For a simple reaction-time experiment where most responses might be 400-500ms, then 1000ms might be a good cut-off. For a complex dual-task experiment though, the mean reaction time might be much longer, so 1000ms might be a ‘reasonable’ response time for that task. If you find that you’re losing more than about 5-10% of your data with that cut-off, maybe you should consider a higher one?
Another, more flexible approach is to calculate the mean and standard deviation of the RT for each subject, then get rid of anything that’s more than two SDs above or below the mean. This is helpful if you have some subjects that are generally quite fast, and some that are generally quite slow – means you keep more of the data from the slow ones than if you used a one-size-fits-all hard cut-off.
Hope that helps!
M.
Pingback: How to analyse reaction time (RT) data: Part 1 « Computing for Psychologists « the neuron club